reduce(归约) 是并行计算中的一个经典问题,他的做法如下:给定一个数组,计算其sum(总和)、min(最小值)、max(最大值)或mean(平均值),这一操作是基本的data parallel primitive。
reduce 最简单的实现是采用 for 循环的方式遍历每个元素并计算结果,但这种方法的效率非常低,那么如何使用 CUDA 来加速和优化这个过程呢?
在这篇文章中,我们将通过 1D reduce 的例子,来一步一步优化程序的性能,将带宽打满,对应的 github repo cuda-reduce-example。
在这篇文章开始之前,我想碎碎念一下。cuda 学习一直都在我的计划日程当中,每次都是从看书或者手册开始,不过进展始终不顺利。最近看到了少数派的这篇文章也许学校根本没有教你如何学习:论什么是真正的自学,他讲了学习的正确打开方式,其中举了一个非常形象的例子
学编程
❌ 错误做法:
我要学习 web 开发 > 某某大师总结的 roadmap(学习路线图) > 天书般的知识体系 > 欺骗自己(我们遇到什么困难,都不要怕!微笑着面对它,加油,✊🤓奥利给!)> 3日后劝退
✔️ 正确做法:
先搞一个简单的个人网站 > 搜索引擎 or GPT 搜怎么做一个个人网站 > 跟着攻略敲 > 遇到问题 > 返回前面继续问 > 重复以上步骤 > 最后做出来一个很垃圾很丑陋的网站,但是能跑,哇好开心 > 我怎么把这个网站变得好看酷炫一些 > 重复以上步骤
看了这个例子仿佛看到了之前学习 cuda 的我,每次都是兴致满满地指定阅读计划,然后打开 cuda 相关的书开始读,最终坚持几天之后就坚持不下去了。我本身对学习 cuda 的动力其实非常强,但是因为使用了错误的方式导致总是半途而废。
那么基于上面这篇文章关于“学习”的理论和指导,对于 cuda 的学习,我们就应该从实践和项目出发,在完成项目的过程中遇到问题再去解决,这篇文章就是这个“学习”思路的第一次尝试。
Introduction
在一开始,我们先介绍 reduce sum 的一个简单实现的流程:假设我们有一个长度是 N 的整数数组,通过 for 循环遍历每一个元素来计算总和,实现流程如下
int cpuSum(int* data, size_t size) {
int sum = 0;
for (int i = 0; i < size; ++i) {
sum += data[i];
}
return sum;
这种方式对于大型数组来说,效率是很低的,为了加速这个过程,并行计算是必不可少的。对于加法来说,它满足交换律和结合律,所以按照任何的顺序对数组进行求和都是可以的。
对于一段程序,可以分为计算密集型和访存密集型,不同的类型优化的目标是不同的。加法的 arithmetic intensity 非常低,这意味着我们需要优化的访存效率,也就是优化其峰值带宽。
Baseline
首先我们来实现一个 CPU 的基线版本,流程如下图所示
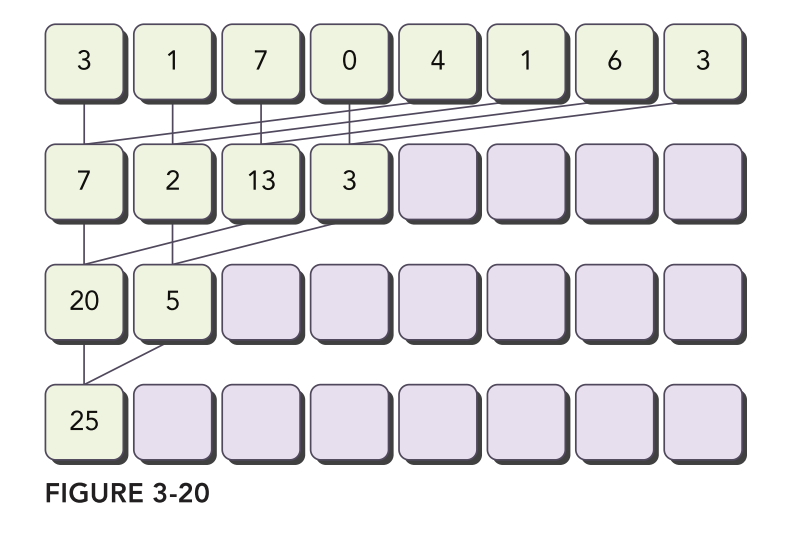
即每次将待处理的数组分成左右两半进行求和,然后不断递归直到处理完所有元素即可,代码如下
int cpuReduceSum(int* data, size_t size) {
// terminate check
if (size == 1) return data[0];
// renew the stride
size_t stride = size / 2;
// in-place reduction
for (int i = 0; i < stride; ++i) { data[i] += data[i + stride]; }
return cpuReduceSum(data, stride);
}
为了评估 baseline 的性能,我们选择大小为 268M(228) 的数组进行测试,结果如下
start profiling reduction with array size 268435456
starting reduction at cpu
cpu reduce elapsed 663.908958 ms, bandwidth 1.617303 GB/s
通过运行上面的 CPU 代码可以看到,带宽利用率非常低,只有 1.6G 左右。
Parallel Reduction 分析
上面的 CPU 版本是一个 sequential 的实现思路,我们直接改写上面的递归方案,实现一个 parallel 的版本,所有的 thread block 同时去处理这个大的数组,这样是不是就可以解决问题呢?
如果要实现这种方案,在每个 block 计算完成之后,需要一个全局同步(global sync),这个同步可以保证每个 block 把自己这部分的数据处理完成,接着再去递归处理剩下的数组,每次递归都可以减少一半要处理的数据。
但是理想是丰满的,现实是骨感的,全局同步在 CUDA 中并不能实现。因为要在硬件上实现这种 feature 成本非常高,特别是对于 GPU 这种 processor 非常多的设备,完全不可行。除此之外,全局同步的机制也会使得程序员倾向于运行更少的 block 来避免死锁(deadlock),这样会显著地减少正在运行的进程数量,从而导致程序的整体效率降低。
如何理解使用更少的 blocks 可以避免 deadlock 呢? 想象一下这种情况,一些 blocks 在执行结束之后,到达了同步点,正在等待另外一些 blocks 执行到同步点。这些正在等待的 blocks 占据了一些资源,而正在执行的 blocks 需要一些计算资源才能执行,在这种情况下,这些需要执行的 blocks 就卡住了,永远不能到达同步点,造成 deadlock。
虽然 CUDA 中没有全局同步,但是有一个 workaround 就是 kernel launch 可以作为一个天然的同步点,所以可以将整个流程分成多次的 kernel launch,这个方式叫做 kernel decomposition,这样硬件和软件的 overhead 都很小,因为硬件不需要支持全局同步,而软件的开销仅仅是多次的 kernel launch。
采用 kernel decomposition,多次 kernel launch 执行的是相同的代码,所有 level 都是一致的,kernel 被递归调用。 输入的 array 被分成多个 chunks,每个 cuda block 都负责处理其中一个 chunk 的 partial sum 结果,可以参考下面这张示意图。
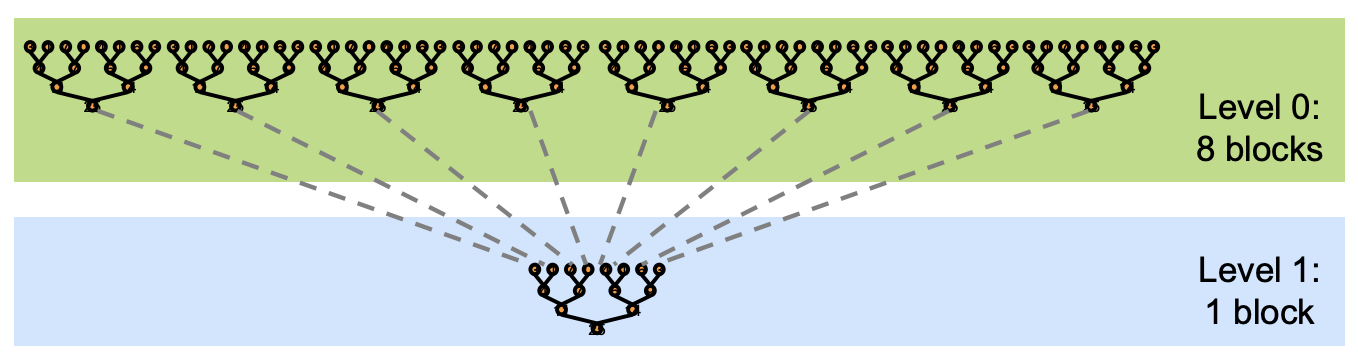
下面,我们实现一下 kernel decomposition,并一步一步对它进行优化。
Reduction-v0
下面我们先实现一下第一版的 reduction 算法,叫做 interleaved addressing,也叫做 pairing,因为他是通过 strided-access 的方式来访问连续内存,和我们平时采用的连续访问有所不同,可以参考下面的示意图。
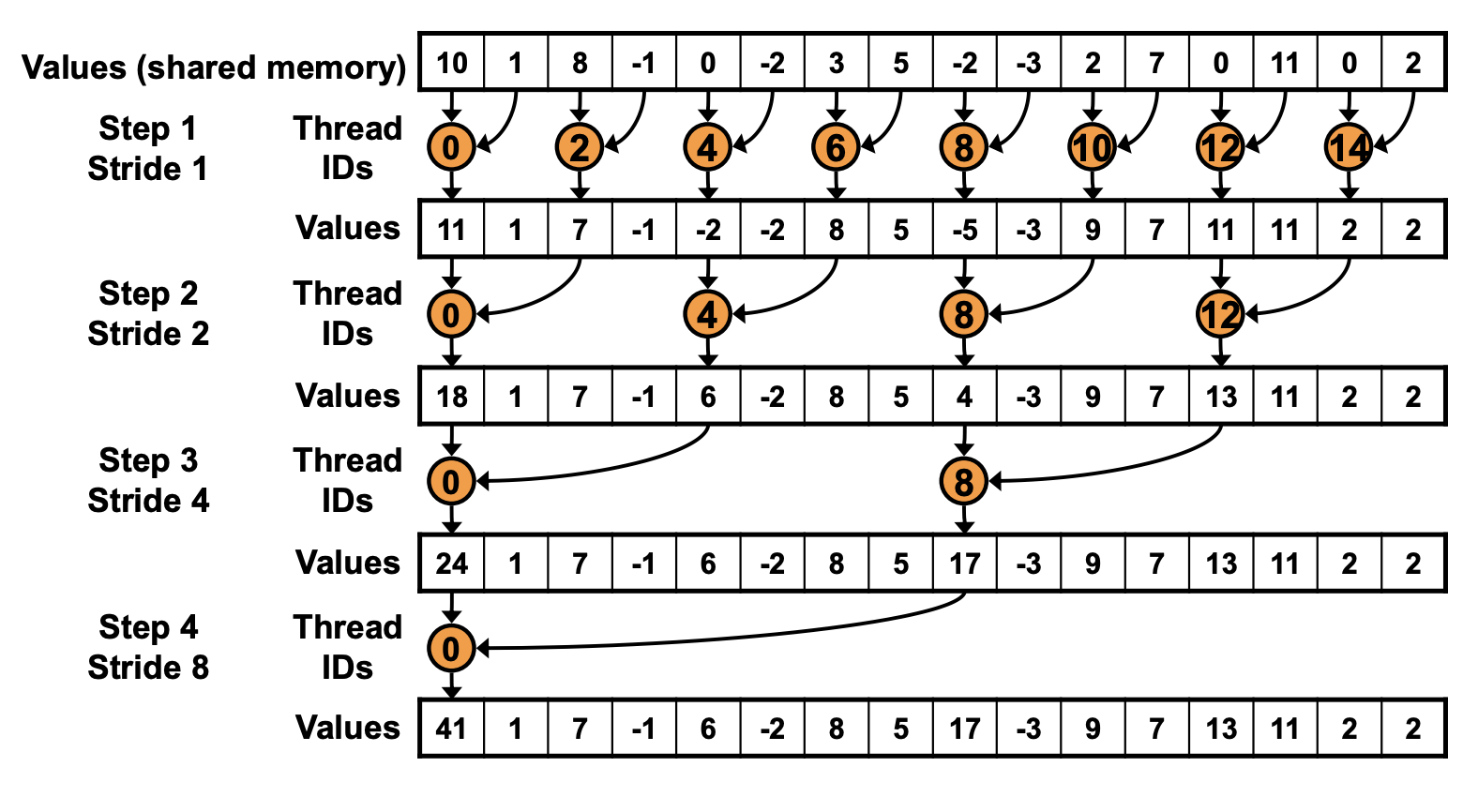
采用这个方法,整个 array 会被分到不同的 cuda block 中,每个 block 中的线程会找到对应的元素执行 reduce 操作,不断循环这个过程。比如第一次 idx=0,2,4... 按照 stride=1 去找到对应的元素执行 reduce,第二次 idx=0,4,8 找到 stride=2 的元素执行 reduce,参考代码如下:
__global__ void reduce0(int* idata_d, int* odata_d, size_t size) {
size_t tid = threadIdx.x;
size_t g_idx = blockDim.x * blockIdx.x + tid;
// if out of boundary, just return
if (g_idx >= size) { return; }
int* idata_b = idata_d + blockDim.x * blockIdx.x;
for (size_t stride = 1; stride < blockDim.x; stride <<= 1) {
if (tid % (stride * 2) == 0) { idata_b[tid] += idata_b[tid + stride]; }
__syncthreads();
}
if (tid == 0) { odata_d[blockIdx.x] = idata_b[0]; }
}
首先获得全局 g_idx,然后找到每个 cuda block 对应的开始位置 idata_b,接着在 for-loop 中每次扩大 stride*2,通过 tid % (stride * 2) == 0 来确定激活的 thread,然后对 tid 和 tid + stride 对应的 element 执行 reduce,最后整个 reduce 结果都存在了当前 cuda block 的第一个元素中。
运行 reduce0 的结果如下
start profiling reduction with array size 268435456
starting reduction at cpu
cpu reduce elapsed 661.640882 ms, bandwidth 1.622847 GB/s, cpu_sum: -133085974
starting reduction at cuda_v0 device 0: NVIDIA GeForce RTX 4090
reduction_v0 elapsed 2.654076 ms, bandwidth 404.563385 GB/s
通过在 CUDA 上实现的 baseline 版本,我们已经获得了 CPU 的 200x 加速,这足以看出并行计算的威力。不过这只是我们的 baseline 版本,我们还可以做一系列优化继续提高其性能,因为 4090 的理论带宽是 1008GB/s,我们只实现了理论带宽 ~30% 的性能。
Reduction-v1
通过上面 profile 性能,我们发现只能实现 ~30% 的理论带宽,那么问题是什么呢?
v0 的问题是 divergence,怎么理解呢?可以看到在第一个 for 循环中,warp 里面只有一半的 threads 是活跃的,另外一半是空闲的,因为我们有一个 if 条件 tid % (stride * 2) == 0 成立才会执行,而到了第一个 for 循环,空闲的 threads 会更多。这个现象被叫做 warp divergence。
如何解决这个问题呢?可以通过修改 for 循环中的 index 成连续的地址来解决这个问题,这么说有点抽象,可以看下面的参考示意图。
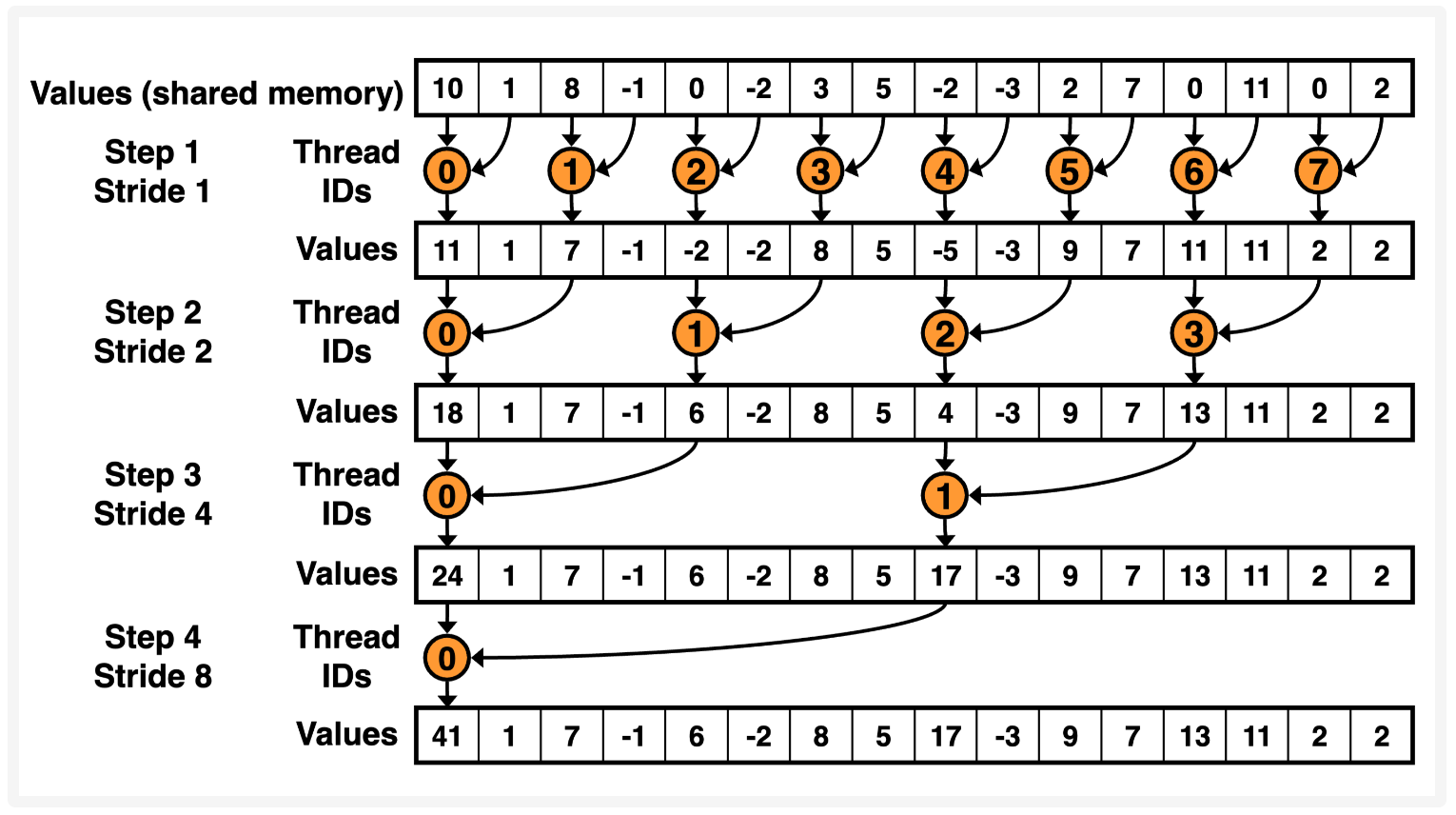
对比 v0,区别在于 thread ids 变成连续了,这样就保证 warp 里面的 threads 都是活跃的,参考代码如下:
__global__ void reduce1(int* idata_d, int* odata_d, size_t size) {
extern __shared__ int sdata[];
size_t tid = threadIdx.x;
size_t g_idx = blockDim.x * blockIdx.x + tid;
// if out of boundary, just return
if (g_idx >= size) { return; }
sdata[tid] = idata_d[g_idx];
__syncthreads();
for (size_t stride = 1; stride < blockDim.x; stride <<= 1) {
int index = tid * (stride * 2);
if (index < blockDim.x) { sdata[index] += sdata[index + stride]; }
__syncthreads();
}
if (tid == 0) { odata_d[blockIdx.x] = sdata[0]; }
}
整体代码逻辑是一样的,增加了 shared memory,同时 index 的计算变成了 index = tid * (stride * 2),可以对照上面的图示推算一下。
运行 profile 可以获得下面的结果。
starting reduction at cuda_v0 device 0: NVIDIA GeForce RTX 4090
reduction_v0 elapsed 2.654076 ms, bandwidth 404.563385 GB/s
starting reduction at cuda_v1 device 0: NVIDIA GeForce RTX 4090
reduction_v1 elapsed 1.597881 ms, bandwidth 671.978455 GB/s
可以看到,在解决了 warp divergence 的问题之后,获得了接近 1.7x 的加速比,下面让我们继续优化。
Reduction-v2
在 v1 中引入了 shared memory,但是我们并没有好好处理 shared memory 的读取问题,这样导致一个问题,叫做 bank conflict。比如在第一次 for 循环中,tid_0 会读取 index=0 和 index=1 对应的元素,而 tid_16 会读取 index=32 和 index=33 的元素,而我们知道 index=0 和 index=32 在同一个 bank 中,而 tid_0 和 tid_16 在同一个 warp 中,这样就触发了 bank conflict。
解决 bank conflict 的常见方式是 padding,不过在这里我们不需要采用 padding,可以想一下现在触发 bank conflict 是因为 tid_0 和 tid_16 读了同一个 bank 的元素,那么很简单让他们读不同的 bank 就可以解决问题了。
如果要同一个 warp 内的 thread 读取不同的 bank,很显然需要他们读取连续的地址,也就是 tid_i 读取 index=i 的元素,而每个 thread 需要读取两个位置的元素做 reduce,所以 tid_i 再按 stride 读取另外一个元素即可,这个就叫做 sequential addressing,可以通过下面的示意图去理解。
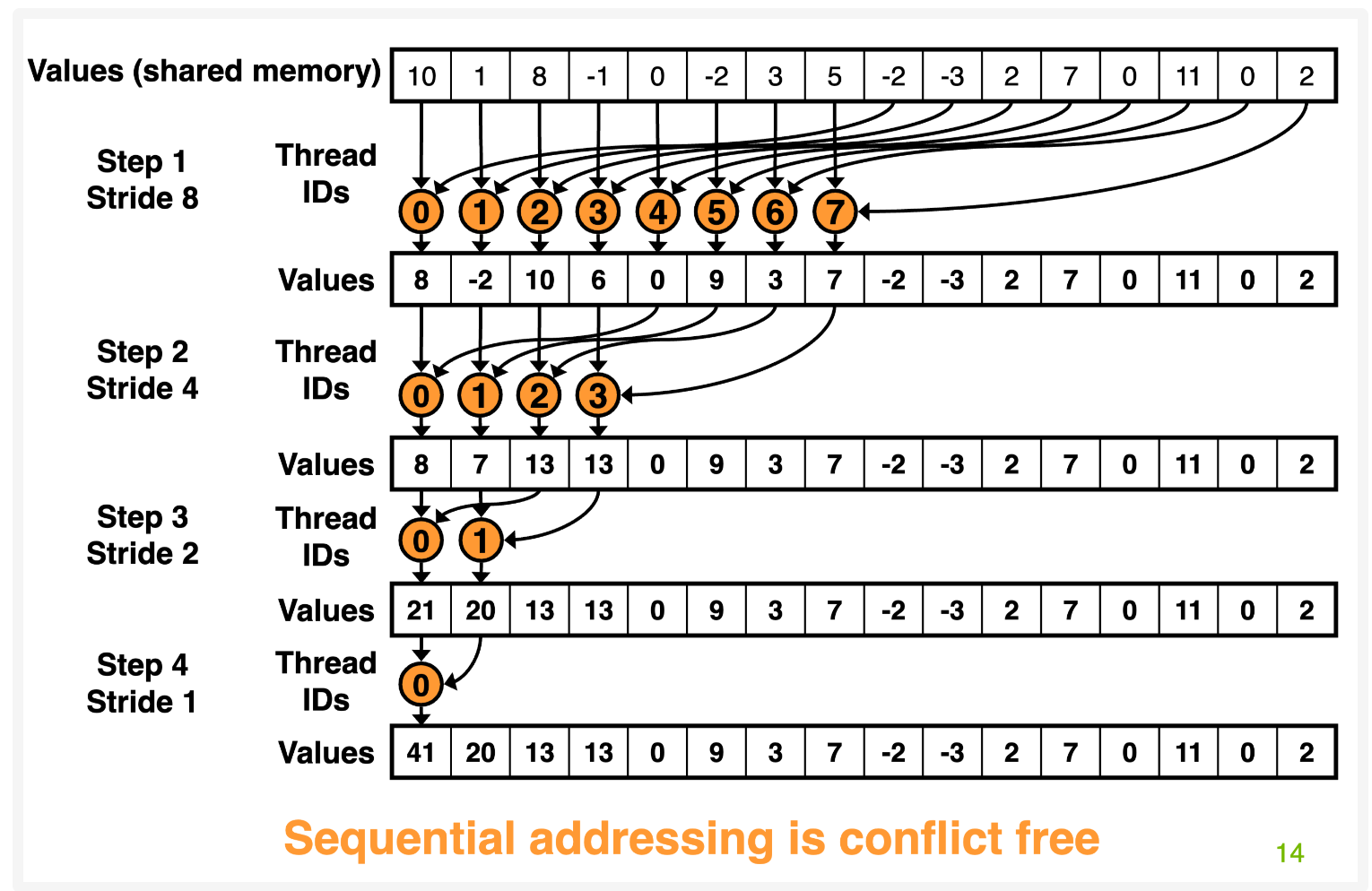
参考代码如下,主要的区别在于 stride,之前是从小到大,现在是从大到小,因为现在是读取连续的内存地址,可以看上面的图帮助理解。
__global__ void reduce2(int* idata_d, int* odata_d, size_t size) {
extern __shared__ int sdata[];
size_t tid = threadIdx.x;
size_t g_idx = blockDim.x * blockIdx.x + tid;
// if out of boundary, just return
if (g_idx >= size) { return; }
sdata[tid] = idata_d[g_idx];
__syncthreads();
for (size_t stride = blockDim.x / 2; stride >= 1; stride >>= 1) {
if (tid < stride) { sdata[tid] += sdata[tid + stride]; }
__syncthreads();
}
if (tid == 0) { odata_d[blockIdx.x] = sdata[0]; }
}
运行 profile 之后可以获得下面的结果。
starting reduction at cuda_v1 device 0: NVIDIA GeForce RTX 4090
reduction_v1 elapsed 1.597881 ms, bandwidth 671.978455 GB/s
starting reduction at cuda_v2 device 0: NVIDIA GeForce RTX 4090
reduction_v2 elapsed 1.564026 ms, bandwidth 686.524353 GB/s
优化之后,看到结果提升比较有限,除了 v1 只是 2-way conflict,另外一个更主要的原因是在第一个 iter 的时候,一半的 thread 都是空闲的,因为 if(tid < stride) 的条件成立才会执行下面的操作,而第一个 iter 下 stride=blockDim.x / 2 所以非常浪费。
Reduction-v3
既然知道了 v2 的问题是另外一半的 thread 是空闲的,我们让他们也执行起来就好了,怎么做呢?很简单,让每个 block 再多读一倍的 data 就可以了,这样另外一半空闲的 thread 就去处理多读的 data,这个方法叫做 First Add During Load,也就是第一次读取的时候,多读一倍的 data,然后做 reduce。
参考代码如下,可以看到唯一的区别就是在执行 for 循环的 reduce 之前,多读了 blockDim.x 的 data,然后做完 reduce 放到 shared memory 里面。
__global__ void reduce3(int* idata_d, int* odata_d, size_t size) {
extern __shared__ int sdata[];
size_t tid = threadIdx.x;
size_t g_idx = (2 * blockDim.x) * blockIdx.x + tid;
// if out of boundary, just return
if (g_idx + blockDim.x >= size) { return; }
sdata[tid] = idata_d[g_idx] + idata_d[g_idx + blockDim.x];
__syncthreads();
for (size_t stride = blockDim.x / 2; stride >= 1; stride >>= 1) {
if (tid < stride) { sdata[tid] += sdata[tid + stride]; }
__syncthreads();
}
if (tid == 0) { odata_d[blockIdx.x] = sdata[0]; }
}
通过 profile 可以得到下面的结果,可以看到提升非常显著,获得了 1.4x 的加速比,可以看到,我们已经达到了理论带宽的 ~90% 了。
starting reduction at cuda_v2 device 0: NVIDIA GeForce RTX 4090
reduction_v2 elapsed 1.564026 ms, bandwidth 686.524353 GB/s
starting reduction at cuda_v3 device 0: NVIDIA GeForce RTX 4090
reduction_v3 elapsed 1.181126 ms, bandwidth 909.083496 GB/s
Reduction-v4
上面的方法已经比较高效了,还有什么优化空间吗?目前代码还可能存在的瓶颈就是 instruction overhead,这个并不是指 load,store,arithmetic 这些核心计算,而是像地址计算,循环这些 overhead。
要解决 instruction overhead,一个方式就是循环展开(unroll loops).
可以从上面的代码看出,随着 for 循环进行,活跃的 threads 会逐渐减少,当 stride <= 32 之后,仅仅只有一个 warp 还在工作。这个时候继续用 for 就比较浪费了,可以直接将 for 循环展开,避免产生 overhead。
在 warp 中,指令是 SIMD1 同步的,所以我们可以节约下面两个指令:
__syncthreads()if (tid < s)
下面是循环展开部分的代码,其他代码和 v3 都是一样的。
// unroll last warp
if (tid < 32) {
volatile int* temp = static_cast<volatile int*>(sdata);
#pragma unroll
for (size_t stride = 32; stride > 0; stride >>= 1) { temp[tid] += temp[tid + stride]; }
}
这里要注意 volatile 关键字,因为我们去掉了 __syncthreads(),所以增加 volatile 防止编译器将中间结果暂存到寄存器或者临时变量里面。
执行 profile 可以看到下面的结果,可以看到实际上提升非常有限了,基本上算是数值波动。
starting reduction at cuda_v3 device 0: NVIDIA GeForce RTX 4090
reduction_v3 elapsed 1.181126 ms, bandwidth 909.083496 GB/s
starting reduction at cuda_v4 device 0: NVIDIA GeForce RTX 4090
reduction_v4 elapsed 1.186848 ms, bandwidth 904.700623 GB/s
Reduction-v5
在 v4 中,我们可以看到 unroll loop 可以带了性能提升,但是我们只做了最后一个 warp 的情况,如果我们在编译期就能知道整个 for 循环的迭代次数,我们可以将整个 reduce 过程都展开。
实际上我们知道整个循环的次数就是由 block_size 决定的,而且对于 GPU 来说,block_size 最大就是 512,同时 CUDA 支持 C++ 的模板函数,所以我们可以定义下面的模板函数。
template<size_t blockSize>
__global__ void reduce5(int* idata_d, int* odata_d, size_t size) {
extern __shared__ int sdata[];
size_t tid = threadIdx.x;
size_t g_idx = (2 * blockDim.x) * blockIdx.x + tid;
// if out of boundary, just return
if (g_idx + blockDim.x >= size) { return; }
sdata[tid] = idata_d[g_idx] + idata_d[g_idx + blockDim.x];
__syncthreads();
if (blockSize >= 512) {
if (tid < 256) { sdata[tid] += sdata[tid + 256]; }
__syncthreads();
}
if (blockSize >= 256) {
if (tid < 128) { sdata[tid] += sdata[tid + 128]; }
__syncthreads();
}
if (blockSize >= 128) {
if (tid < 64) { sdata[tid] += sdata[tid + 64]; }
__syncthreads();
}
// unroll last warp
if (tid < 32) {
volatile int* temp = static_cast<volatile int*>(sdata);
#pragma unroll
for (size_t stride = 32; stride > 0; stride >>= 1) { temp[tid] += temp[tid + stride]; }
}
if (tid == 0) { odata_d[blockIdx.x] = sdata[0]; }
}
首先 blockSize 作为模板参数需要在编译期指定。整个函数的开头和结尾都是一样的,完全展开的部分主要在中间,通过判断不同的 blockSize 来执行 strided reduce。而且由于 blockSize 是编译时变量,所以所有的 if 判断都在编译期执行。
运行 profile 之后的结果如下,可以看到结果也没什么变化,因为 kernel launch 的 blockSize=128,所以提升比较有限,如果设置更大的 blockSize 应该可以获得更好的提升。
starting reduction at cuda_v4 device 0: NVIDIA GeForce RTX 4090
reduction_v4 elapsed 1.186848 ms, bandwidth 904.700623 GB/s
starting reduction at cuda_v5 device 0: NVIDIA GeForce RTX 4090
reduction_v5 elapsed 1.203060 ms, bandwidth 892.508850 GB/s
Reduction-v6
可以看到 v5 已经非常接近理论带宽了,下面我们分析一下目前的算法复杂度。
首先分析 step complexity,对于并行算法来说,如果一共有 N 个元素,每次都是 pairwise 做 reduce,第一次处理完之后,剩下就是 N/2 个元素,第二次处理完就是 N/4 个元素,以此类推,假设一共执行 s 步,就有 \(N/2^s = 1\) 可以得到 \(s = O(\log N)\).
接着分析 work complexity,假定一共有 N 个元素,定义 \(N=2^D\),那么第一步要执行 \(2^{D-1}\) 次 operation,第二次是 \(2^{D-2}\),以此类推,可以得到
$$ \sum_{S \in [1..D]} 2{D-S} = N-1 $$
也就是说整体的 work complexity 是 \(O(N)\)。
结合 step complexity 和 work complexity,我们可以分析 time complexity。如果有 P 个 threads 并行处理,那么 work complexity 就是 \(O(N/P)\),但是 step complexity 仍然是 \(O(\log N)\) 因为不管使用多少 threads,都只能每次处理一半的数据,然后进行进程间同步。所以整体的 time complexity 就是 \(O(N/P + \log N)\)。
对于 sequential reduction 来说,时间复杂度是 \(O(N)\),而对于并行计算,只需要考虑一个 thread block 内,因为 block 之间并不存在任何同步,彼此是独立运行,如果在一个 block 内 launch N 个 threads,即 \(N=P\), 那么时间复杂度就是 \(O(\log N)\)。
接下来我们分析一下整体的 cost,对于并行算法来说,现在的时间复杂度是 \(O(\log N)\),我们需要 launch N 个 threads,那么整体的 cost 就是 \(O(N \log N)\),这个并不是最有效的 cost。
对于 time complexity \(O(N/P + \log N)\) 来说,假设 launch P 个 threads,那么 cost 就是 \(O(N + \log N * P)\),我们希望 cost 是 \(O(N)\),所以有 \(\log N * P = N\) -> \(P = O(N / \log N)\),这就是 Brent’s theorem 效率最优的方案。
在实际使用中,每个 thread 处理更多的 data 会更好,这样有三个好处:
- 每个 thread 处理更多的 data 可以更好的隐藏 latency;
- 处理更多的 data 可以减少递归的 kernel 调用次数;
- 可以减少 reduce 最后阶段 block 中 kernel launch 的开销,因为需要 launch 更少的 kernel;
通过上面的分析,我们知道要提高效率的方法就是让一个 thread 处理更多的 data,对于具体的实现,就是将 First Add During Load 变成 Multiple Adds During Load,通过一个 while loop 尽可能多的计算 reduce。
通过预设一个固定的 gridSize 值,通过 while 循环,当前的 grid 处理完对应的 array 之后,移动到下一个部分,直到完成整个 array 的遍历。
示例代码如下,增加一个 while 循环,每个 block 处理预设的 array 长度,接着移动到 array 的下一个部分,直到处理完所有的 array。
...
size_t tid = threadIdx.x;
size_t g_idx = (2 * blockSize) * blockIdx.x + tid;
size_t gridSize = (blockSize * 2) * gridDim.x;
sdata[tid] = 0;
while (g_idx < size) {
sdata[tid] += idata_d[g_idx] + idata_d[g_idx + blockSize];
g_idx += gridSize;
}
__syncthreads();
...
通过 profile 可以看到结果如下,性能又获得了显著的提升(892->920),之前 gridSize 太大了需要很多
starting reduction at cuda_v5 device 0: NVIDIA GeForce RTX 4090
reduction_v5 elapsed 1.203060 ms, bandwidth 892.508850 GB/s
starting reduction at cuda_v6 device 0: NVIDIA GeForce RTX 4090
reduction_v6 elapsed 1.167059 ms, bandwidth 920.040771 GB/s
Reduction-v7
实际在 v6 中已经实现了比较好的优化效果,带宽利用率达到了 90% 以上,最后我想聊的一个方案是通过 warp shuffle 的方式进行 reduce,算是一种新的思路。
warp shuffle 可以让一个 warp 内的 thread 彼此交换数据,不需要依赖 shared memory,所以效率比较高,缺点就是不能跨 warp 进行数据交换。
所以 warp shuffle 适用于最后阶段的 reduce 操作,这个时候往往只有一个 active warp,在之前的方案中我们采用了 unroll 去处理。
下面是采用 warp shuffle 进行 warp reduce 的代码。
__inline__ __device__ int warpReduce(int localSum) {
localSum += __shfl_down_sync(0xFFFFFFFF, localSum, 16);
localSum += __shfl_down_sync(0xFFFFFFFF, localSum, 8);
localSum += __shfl_down_sync(0xFFFFFFFF, localSum, 4);
localSum += __shfl_down_sync(0xFFFFFFFF, localSum, 2);
localSum += __shfl_down_sync(0xFFFFFFFF, localSum, 1);
return localSum;
}
shfl_down_sync 第一个参数是表示 warp 内激活的 thread 数,第二个是要交换的数据,第三个是 offset,即偏移之后的 thread id。所以第一行就是说 warp 内前 16 个 thread 分别和后 16 个 thread 交换变量 localSum,即 tid0 获得 tid16 对应的 localSum 然后和自己本身的 localSum 变量求和,所以这样就实现了前 16 个 thread 和后 16 个 thread 做 reduce 的效果,后面以此类推,最终 localSum 就是整个 warp 对应的 32 个数据做 reduce 的结果。
通过 profile 可以获得下面的结果,可以看到效率也没有进一步提高了,不过这种算是一种通过 warp shuffle 进行 reduce 的思路。
starting reduction at cuda_v6 device 0: NVIDIA GeForce RTX 4090
reduction_v6 elapsed 1.167059 ms, bandwidth 920.040771 GB/s
starting reduction at cuda_v7 device 0: NVIDIA GeForce RTX 4090
reduction_v7 elapsed 1.176119 ms, bandwidth 912.953491 GB/s
Summary
这篇文章主要是记录了 cuda reduce step by step 的优化过程,从 cpu 版本到最终的 v7 版本不断优化过程。文章主要参考 cuda webinar2 对应的内容,通过写下来全部的过程又进一步加深了理解。就像文章最开始说的,这篇文章通过 case study 的方式来学习新的东西,而不是像之前传统的学习过程,通过阅读大部头书来学习一个一个零散的知识点。通过 case study 的过程,中间遇到不会的再去学习,不仅能够加深对新知识点的理解,同时最终的成果类似完成了一个项目,带来了更大的成就感。
总体来说,这篇文章把 cuda 里面的一些基础内容都讲了,算是一个简单的入门,不过 cuda 的东西太多太杂了,还需要继续学习成熟的 cuda 代码以掌握更多相关的高级特性和写法。
Reference
#blog #cuda
-
https://en.wikipedia.org/wiki/Single_instruction,_multiple_data ↩︎