TL;DR
KV4
总结了几种优化 KV4 量化的方法,优先级从高到低如下:
- Per-Channel Key 量化:简单高效,解决 key 上 outlier 问题。
- Pre-RoPE Key 量化:需要修改 transformers forward 代码和 attention kernel。
- Block Input Module Rotate:引入旋转矩阵减弱 outlier 影响。
- Dynamic Per-Token Value Quant:每个 token 独立量化,隔离误差。
- Non-Uniform 量化:通过 k-means 实现非均匀量化,反量化时使用 indices select。
不推荐的方法包括 SmoothAttention、Dense-and-Sparse 和 Q-Norm。
W4A8
总结了几种优化 W4A8 量化的方法,优先级从高到低如下:
- Block Output Module Smoothing:减弱 A8 上 outlier 对精度的影响。
- Weight Clipping:通过 grid search 找到最优 clip factor,简单且有效。
- Progressive Group Quantization:两步量化,提升计算效率。
- Sensitivity-based Non-Uniform:提升显著,有理论支撑,但社区使用较少。
不推荐的方法包括 Activation-Aware Channel Reordering 和 Dense-and-Sparse Quantization。
Introduction
W4A8KV4 这种量化方案是指在 LLM 推理的过程中,weight 使用 4bit,activation 使用 8bit,kv cache 使用 4 bit,这样减少显存的使用(4bit),同时保证精度不会有太多的损失(8bit),可以使一些显存比较小 GPU 也能跑大的(>70B)的模型。
目前 LLM 量化的主流方案有两种:W4(8)A16 和 W8A8:
- W4(8)A16 是 weight-only 的量化,即只量化 weight 到对应的 bit 位,在 runtime 的时候将其反量化回 fp16 进行推理,代表性的方案是 GPTQ1(8bit) 和 AWQ2(4bit)。
- W8A8 则是对 weight 和 activation 都进行 8bit 量化,比如采用 int8 或者 fp8,可以直接利用 TensorCore 进行效率更高的低位计算,由于 fp8 表示的数值范围更广,直接进行量化在精度上损失也不大,不过对于 int8 要缓解精度问题,代表性的方法是 SmoothQuant3。
除了对 weight 和 activation 进行量化外,另外一个可以量化的对象是 kv cache,特别是在 long context 的场景下,kv cache 也会占据很多空间,目前广泛应用的做法就是 8bit 量化,减少一半的存储和带宽,同时精度上几乎无损。
如果要继续把量化的效果推到极致,就需要继续降低量化的 bit 位,所以目前社区在研究 W4A8 的方案,致力于进一步降低 weight 的存储和带宽压力,使用算力更高的低位运行,同时对于 kv cache 也希望将 8bit 降低到 4bit。
首先为了跟踪社区最新的进展,先简单走读下面三篇文章,然后再列出一些后续的优化方向进行讨论。
- SqueezeLLM: Dense-and-Sparse Quantization
- KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving
论文走读
KVQuant 和 SqueezeLLM 都是 Berkeley SqueezeAILab 出的文章,KVQuant 这篇文章专门研究低 bit kv cache 量化该如何做,里面的方法大量引用了 SqueezeLLM,写得比较粗略,所以需要看 SqueezeLLM 来具体了解其方案。
QServe 是 MIT han-lab 出的文章,主要研究 W4A8KV4 的问题,SmoothQuant 和 AWQ 也出自 han-lab,所以 QServe 里面也借鉴了很多他们的思想。
SqueezeLLM
这篇文章主要是研究 3bit weight-only 量化如何降低精度损失,他观察到下面两个现象:
- weight distribution 是 non-uniform 的,而此前大部分方法都是将 weight 均匀地划分到多个区间;
- weight 存在一些 outlier,这些 outlier 会使得整体量化的 range 变大从而影响量化的精度。
Sensitivity-Based Non-uniform Quantization
如何理解 non-uniform distribution?下面是论文中展示的一个 output channel 的权重分布图。
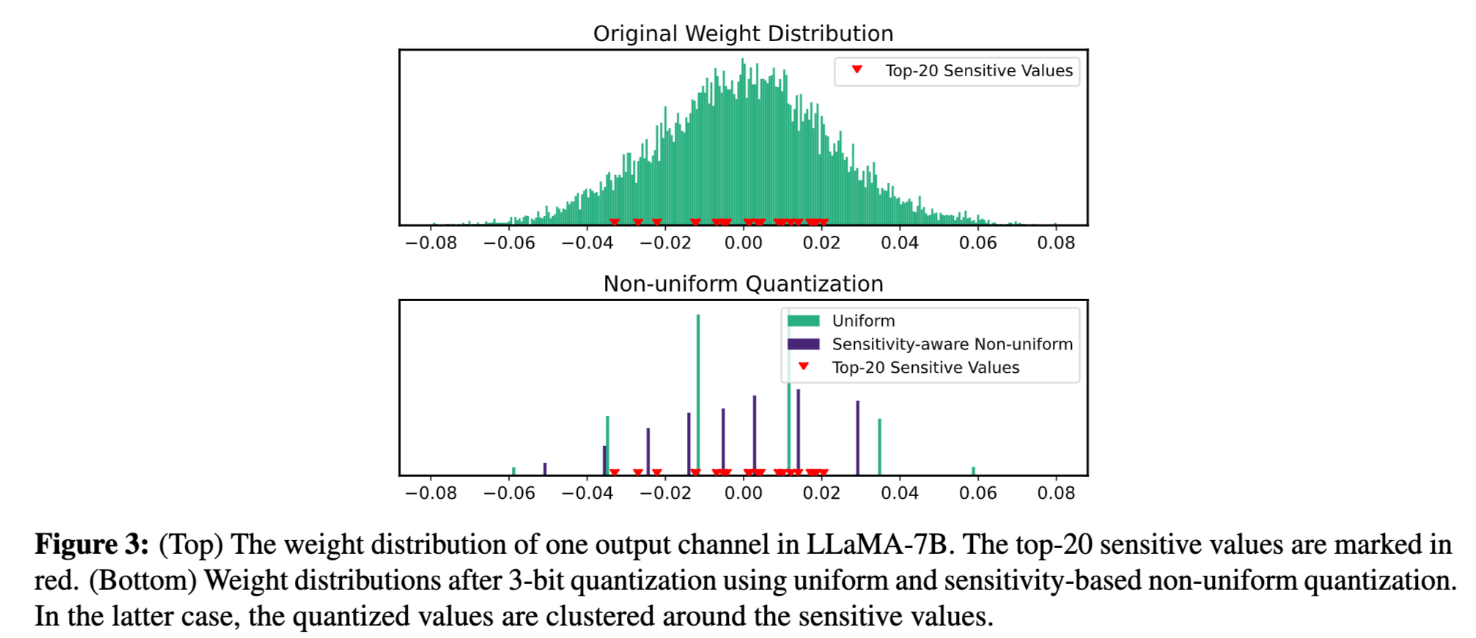
从上面的图可以看到 weight 实际上是服从 normal distribution 而不是 uniform distribution,所以将 weight 量化到均分的区间是 sub-optimal 的。
后续的问题转换成了一个 k-means 问题,因为我们的目标是要找到 k 个离散的值能够最好的保留 weight 的原始分布,之前的做法就是在 quant range 之内均匀的采样 k 个值,比如 int8 就是均匀的采样 [0, 255]。
可以 formulate 成下面的公式,对于所有 weight,计算量化前后的 error。 \[Q(w)^* = \arg\min_Q \| W - W_Q \|_2^2\]
后续作者又发现了并非所有的 weight 都同等重要,有一些 sensitive value 会对 最终的 loss 影响更大,所以应该考虑将 k-means 的中心点往 sensitive value 上靠,以保证这些值能够更好的恢复。
如何找到哪些值是 sensitive 的?可以通过下面对量化后的权重的 loss 进行 Taylor 展开
\[\mathcal{L}(W_Q) \simeq \mathcal{L}(W) - \mathbf{g}^\top (W - W_Q) + \frac{1}{2}(W - W_Q)^\top \mathbf{H} (W - W_Q)\]
考虑到模型训练收敛,那么梯度是0,最终简化成如下
\[Q(w)^* = \arg\min_Q (W - W_Q)^\top \mathbf{H} (W - W_Q)\]
所以可以看到,weight 的 sensitivity 取决于其对应的 Hessian 矩阵,由于二阶矩的计算复杂度,可以参考 GPTQ 将其转换成 Fisher information matrix,通过calib set \(D\) 进行离线计算
\[H \simeq \mathcal{F} = \frac{1}{|D|} \sum_{d \in D} \mathbf{g}_d \mathbf{g}_d^\top\]
最终可以获得 k 个聚类中心来实现 non-uniform 量化,权重在进行量化之后存储的结果是其对应中心点的 indices,反量化的过程就是通过 indices 选择对应的中心点。也可以通过上面的分布图看到,non-uniform 相比于常规的 uniform 量化,可以更好地保持 sensitive value 的结果。
Dense-and-Sparse Quantization
作者继续分析 weight 的分布,发现其中存在一些 outlier,但是比例非常小,只有 ~0.1%,具体可以看下面这张图,可以看出 99.9% 的权重都分布在 10% 的 range 内,但是有 0.1% 的权重分布在另外 90% 的 range。
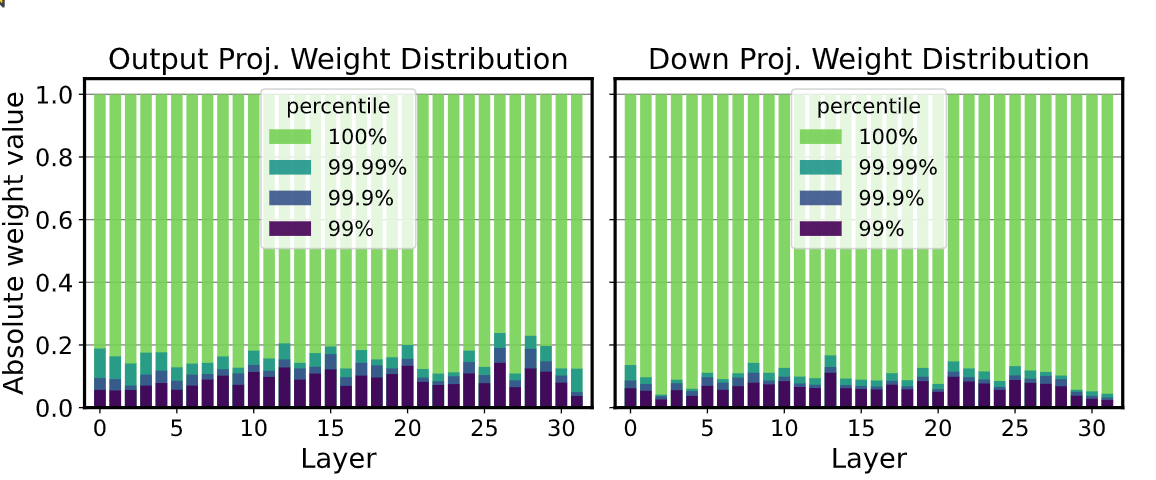
对于量化来说,如果 range 非常大就容易造成性能损失,特别是在低比特量化下,所以一个简单的想法就是将这些 outlier 分离出来不量化,又因为他们的数量很小,所以可以稀疏存储,那么权重可以分成 D 和 S 两种。
\[D = W[T_{\min} \leq w \leq T_{\max}] \quad \text{and} \quad S = W[w < T_{\min} \text{ or } w > T_{\max}]\]
除了 outlier ,最后作者还试了一下将部分 sensitive value 也分离出来,也有一定的精度提升。
下面是不同的方法获得的结果,在 C4 下评估 ppl。
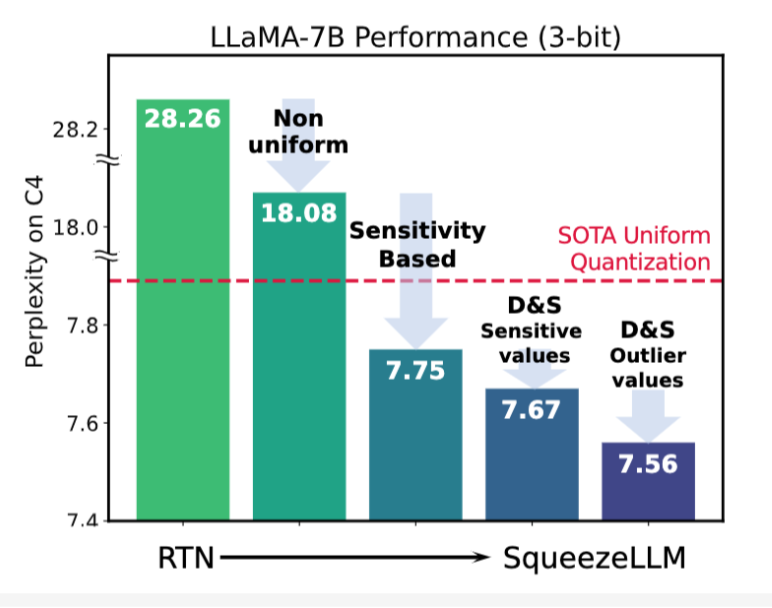
可以看到采用 non-uniform 量化 + sensitivity 的提升已经非常大了,后续 Dense&Sparse 相比之下提升就非常微弱了。
我觉得这是合理的,因为 weight 中的 outlier 数值范围其实并没有很大,另外比例也很少,特别是当模型大了之后,这个现象会更加缓解。
KVQuant
KVQuant 对 kv cache 的分布进行分析,在优化 kv quant 量化上使用了下面的方法:
- 对 key 采用 per-channel 的量化方式;
- 对 key 采用 Pre-RoPE 之前做量化;
- 对 kv cache 采用了逐层 non-uniform 量化;
- 类似 dense-and-sparse 的方法,分离出 outlier;
- 对量化中心做 normalize 消除分布偏移的问题;
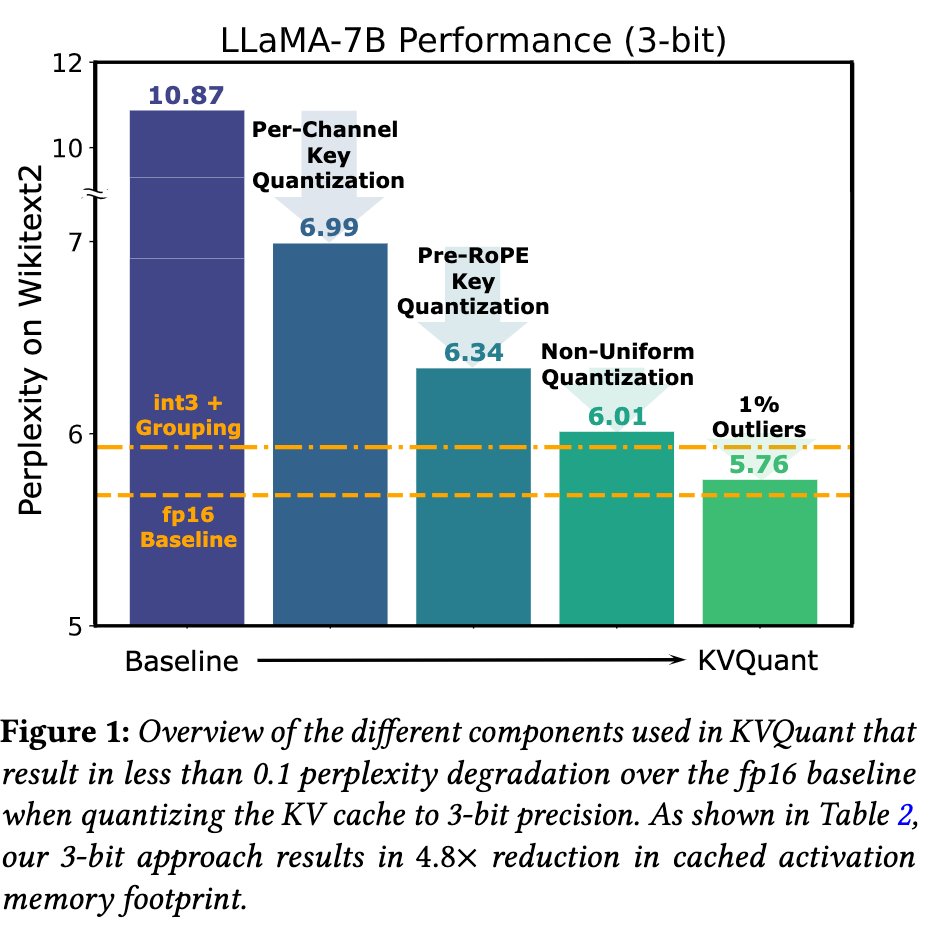
上面是不同方法对精度的改善,可以看到 1) 和 2) 对精度提升非常显著;而 3) 和 4) 基本沿用了 squeezeLLM 中的方法,相比之下提升已经比较小了;对于 5)提升非常微弱,直接没有放到上面进行对比。
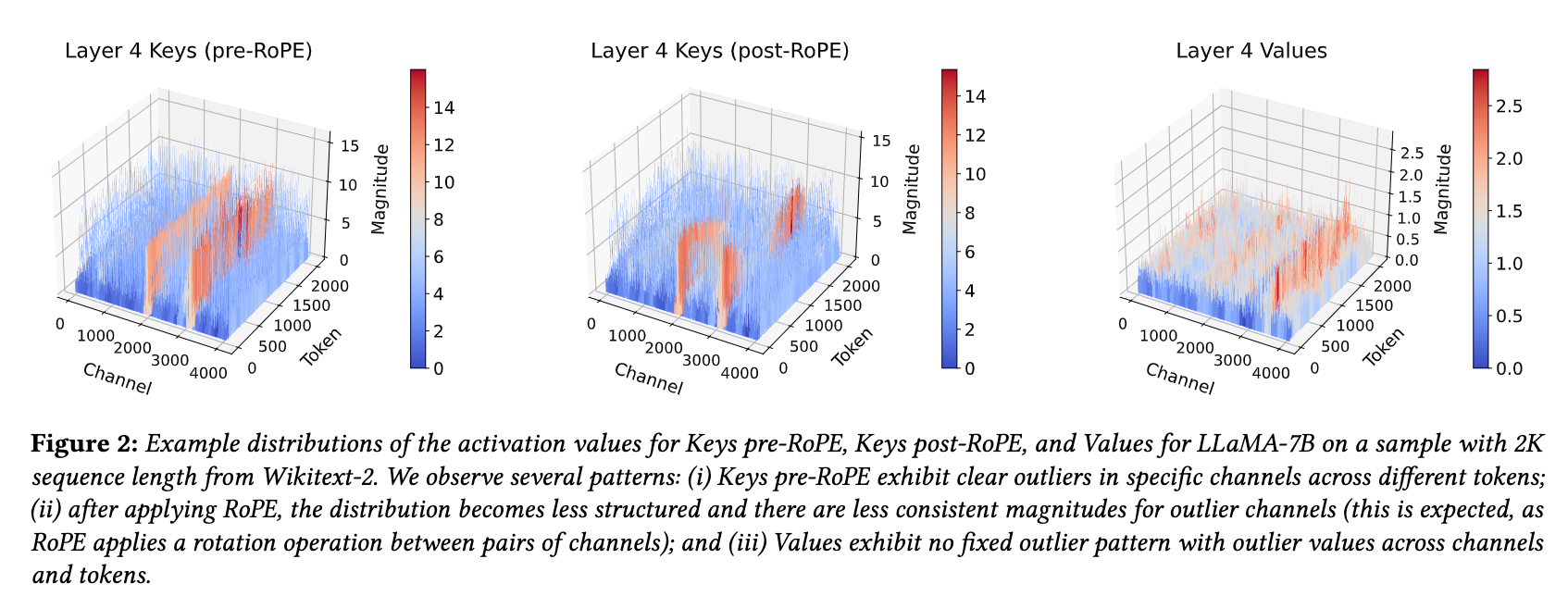
论文展示了 kv cache 的分布情况如下,可以看到 pre-RoPE 之前的 key outlier 分布相比 post-RoPE 有更好的一致性,而且 value 的 outlier 相比于 key 并不显著,所以对 key 采用 pre-RoPE per-channel 量化已经是简单有效的方案。
QServe: W4A8KV4
这篇文章有两个部分,一个部分介绍量化算法 QoQ 实现 W4A8KV4,第二个部分介绍 QServe system 来高效推理 W4A8KV4,QoQ 和 QServe 是 co-design 的,我们主要分析量化算法 QoQ,过程中也会提到推理效率相关的问题。
Why W4A8KV4
首先作者分析为什么要继续做 KV4 量化,因为 attention 大部分情况都是 memory-bound,所以量化 KV Cache 到更小的 bit 位可以减少带宽实现加速。
接着分析了做 W4A8 的收益,在下面的 roofline 分析中,W4A8 可以在各种情况下都保证性能最优。
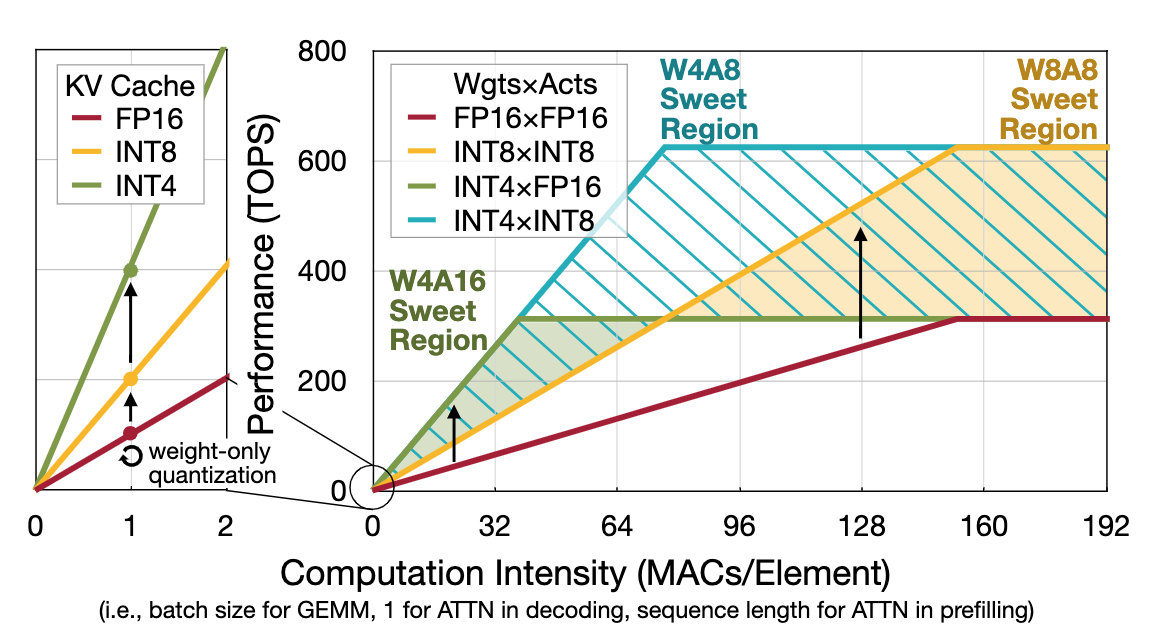
最后分析了为什么不进一步做 W4A4?除了精度上的问题之外,W4A4 并不会比 W4A8 实现更快的加速,因为对于 \(m\times n \times k\) GPU GEMM,在 k 维度上并不能并行,最终会成为瓶颈。
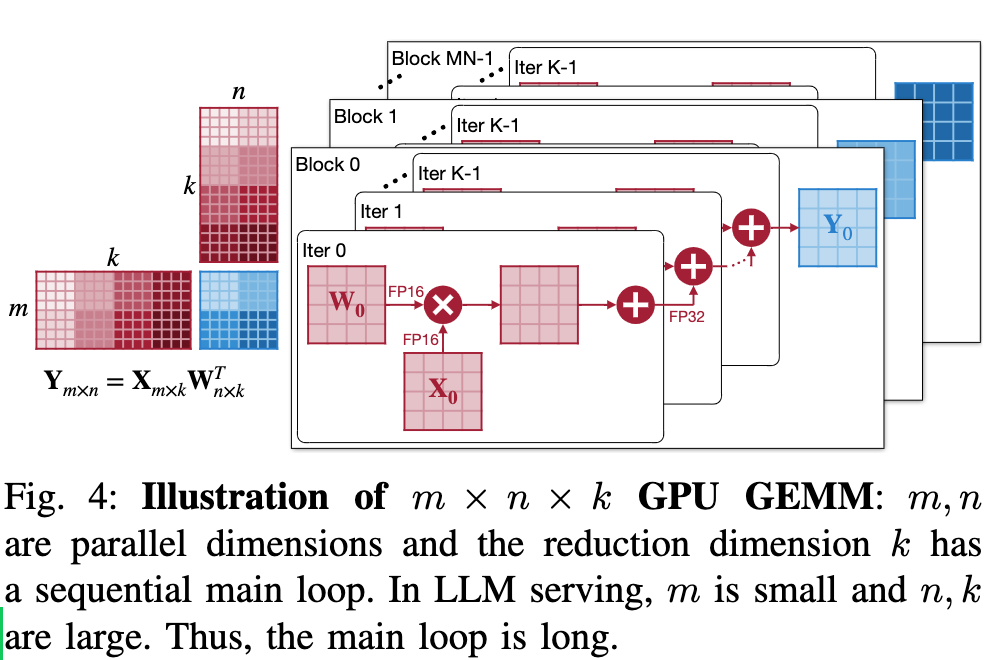
量化方案的 GEMM 分析
下面分析了 W4A16,W8A8 以及 W4A4 在 GEMM 流程和效率。
W4A16 是 weight-only GEMM,流程如下。其中反量化的流程需要在 CUDACore 上执行,然后 fp16 GEMM 可以在 TensorCore 上执行,所以 weight-only kernel 需要好好优化反量化的过程,使其不能成为 bottleneck。
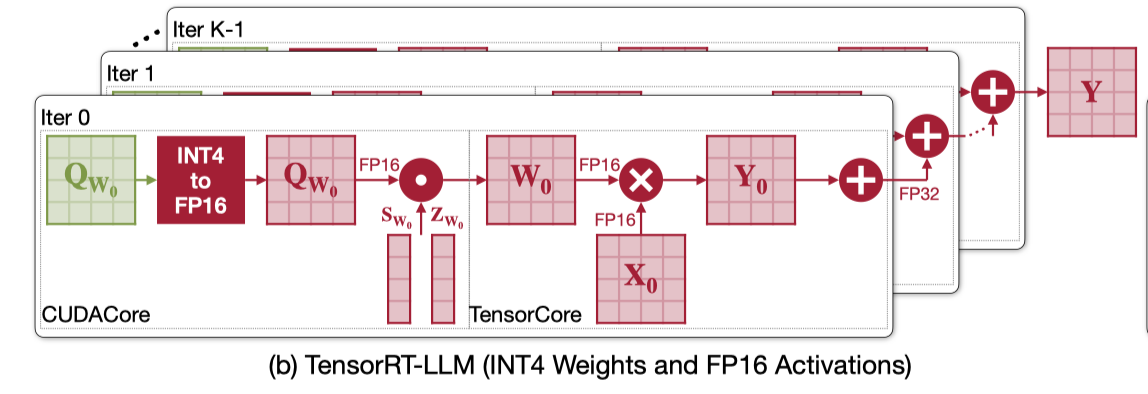
W8A8 可以是 INT8 GEMM 或者是 FP8 GEMM,流程如下。W8A8 除了可以直接使用 TensorCore 进行低比特 GEMM 运算之外,他的反量化也只需要在最终的结果上做一次,所以效率非常高。
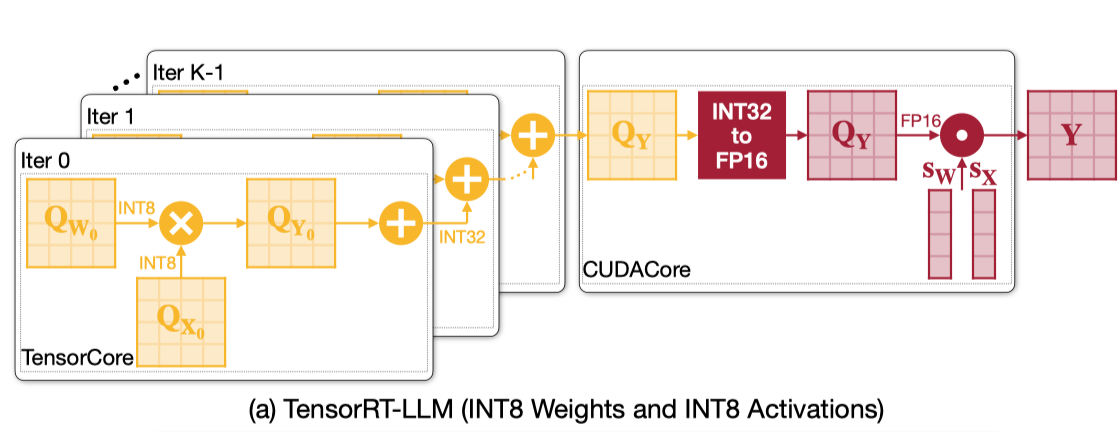
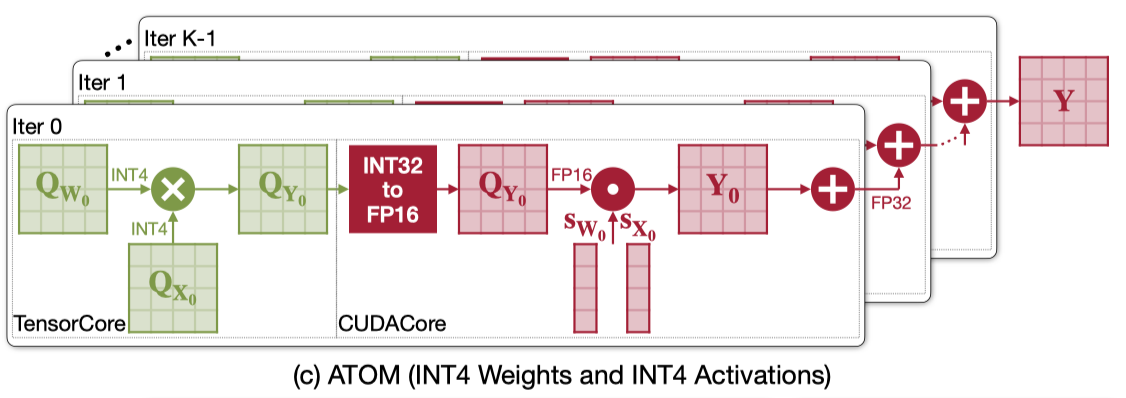
之前一个关于 W4A4 的工作 ATOM 的流程如下。INT4 GEMM 可以使用高效的 TensorCore 来执行,但是后面需要对每次 partial sum 的结果采用 CUDACore 做反量化效率就非常低了。除此之外,他还需要两组寄存器,一组存 FP32,一组存 INT32,也会造成 register-bound 的问题。至于为什么 ATOM 要这样设计,没有具体去看这篇论文了,不过最终结果就是他的 GEMM 流程效率非常低。
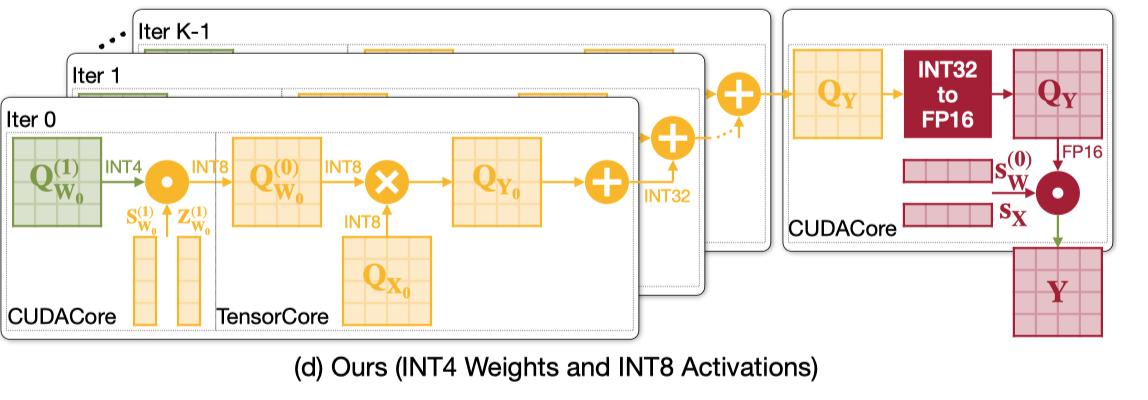
根据上面 3 组 GEMM 的流程,执行 W4A8 最高效的方案如下。采用两阶段量化的方式,第一阶段是 W4 反量化到 W8 的过程,第二阶段采用 W8A8 的思路,选择 weight 反量化而不是 partial sum 反量化可以进一步减小寄存器的压力。
Progressive Quant
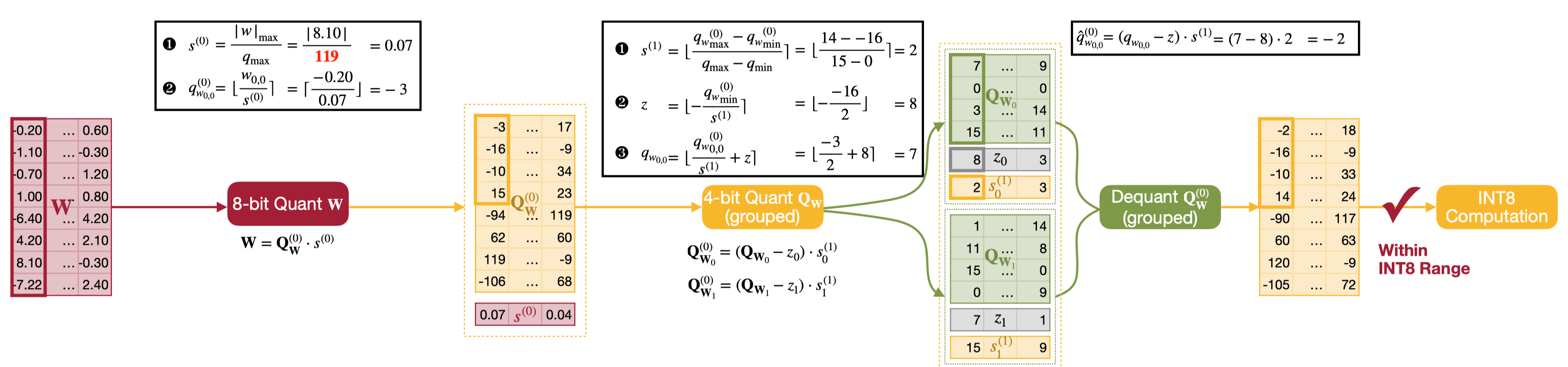
基于上面的方案,从 fp16 到 int4 采用两阶段量化,第一阶段使用 per-channel symmetric 将 fp16 量化到 int8,第二阶段使用 group-wise asymmetric 将 int8 量化到 int4。反量化的过程只需要将 int4 反量化到 int8,然后调用 int8 GEMM 进行计算就行了,具体流程可以看下面的示意图。
另外一种方案是直接量化到目标精度,比如从 fp16 通过 group-wise asymmetric 直接量化到 int4,这时 scale 是 fp16,为了在推理过程中能够将 int4 反量化回 int8 进行计算,对 scale factor 进行 per-channel int8 量化获得新的 int8 scale factor。最后在推理过程中,使用这个 int8 scale factor 进行 group-wise 反量化,具体流程可以看下面的示意图。
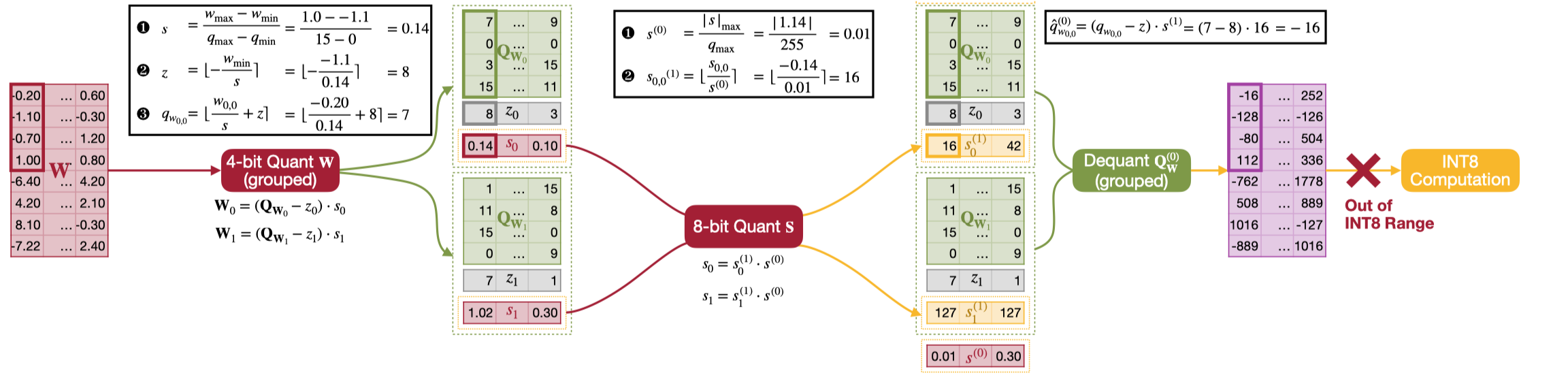
可以看到第二种方式会导致反量化的 int8 处于数值范围外,在数值范围内的结果也不正确,这里我其实不太理解这样可以对 scale factor 做量化,不过这种方式反正是错的,并不可行。
除此之外,论文还基于方案一推导了反量化的流程,最终将 int8 的范围从 [-127, 127] 缩小到 [-119, 119] 来保证反量化过程中不会出现数值越界的问题,减少了 kernel 里面处理越界的开销。
SmoothAttention
和 KVQuant 文章中发现的现象一致,这篇论文也发现了 Key 具有 outlier 的问题,而 value 不存在。而 Attention 的计算是 \(QK^T\),其中 K 需要做量化,而 Q 不用,所以根据 SmoothQuant 的经验,可以将 K 的 outlier 转移到 Q 上以减少 K 量化的困难,有下面的公式。
\[\mathbf{Z} = (\mathbf{Q} \mathbf{\Lambda}) \cdot (\mathbf{K} \mathbf{\Lambda}^{-1})^T, \quad \mathbf{\Lambda} = \operatorname{diag}(\lambda)\]
为了减少额外的 kernel 开销,同样可以把 \(\Lambda\) 吸收到权重里面,不过考虑到 Q 和 K 在算 GEMM 之前会经过 RoPE,所以并不能直接吸收。
观察到 RoPE 会对 channel i 和 i+D/2 进行配对,代码如下
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
cos = cos.unsqueeze(unsqueeze_dim)
sin = sin.unsqueeze(unsqueeze_dim)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
可以推导一下,只需要满足下面的限制,就可以将 \(\Lambda\) 穿过 RoPE 融合到权重里面。
\[\lambda_i = \lambda_{i + \frac{D}{2}} = \max \left( \max\left( \lvert \mathbf{K}_i \rvert \right), \max \left( \lvert \mathbf{K}_{i + \frac{D}{2}} \rvert \right) \right)^\alpha\]
General LLM Quant Optimization
对于 W4A8 这种低比特量化,每个 linear 的 activation outlier 仍然是主要需要优化的问题。不像 SmoothQuant 对每个 linear 做相同的优化,这篇文章对 linear 做了不同的分类,不同的 linear 采用了不同的策略,同时也采用了一些比较通用的 trick 来进一步改善精度。
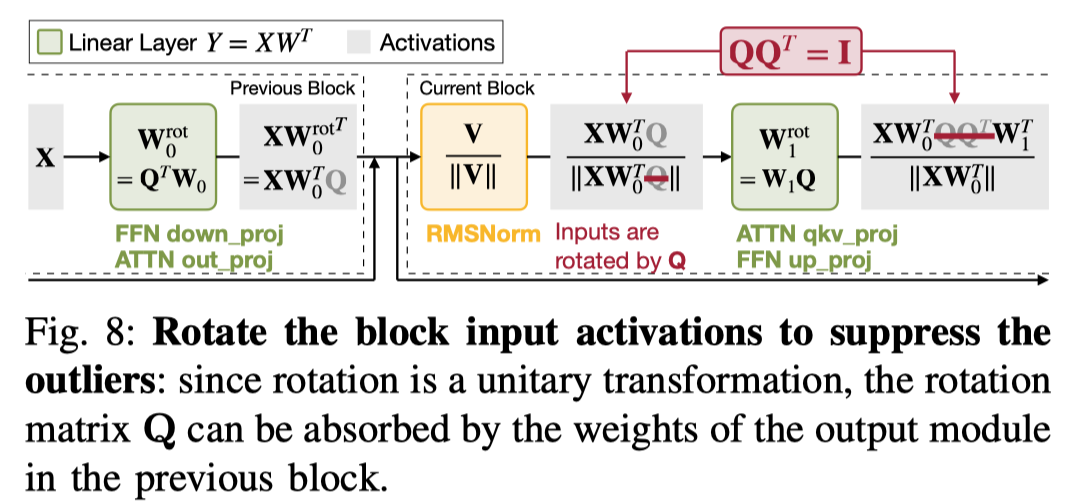
1) Block Input Module Rotation:对每个 block input activation 进行旋转来压缩 outlier,旋转可以通过乘上旋转矩阵 Q 来实现。同时由于旋转矩阵是单位阵,还可以将 Q fuse 到上一层最后一个 linear 的权重中来减少 kernel 的开销,最终的操作等价于对相邻的两个 linear 权重做修改,和 SmoothQuant 非常像,区别在于这里用的旋转矩阵。
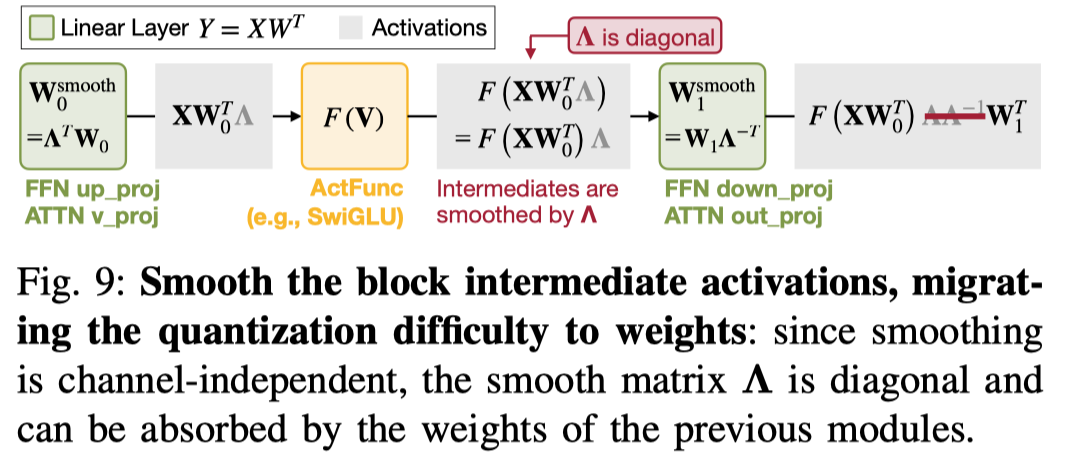
2) Block Output Module Smoothing:output module 是指生成 block output 的 linear,可以它们的输入做 smooth 来减少量化难度。由于 smooth 是 per-channel 的,所以又可以将这个过程 fuse 到前后两层对应的 weight 上,可以参考下面的示意图。
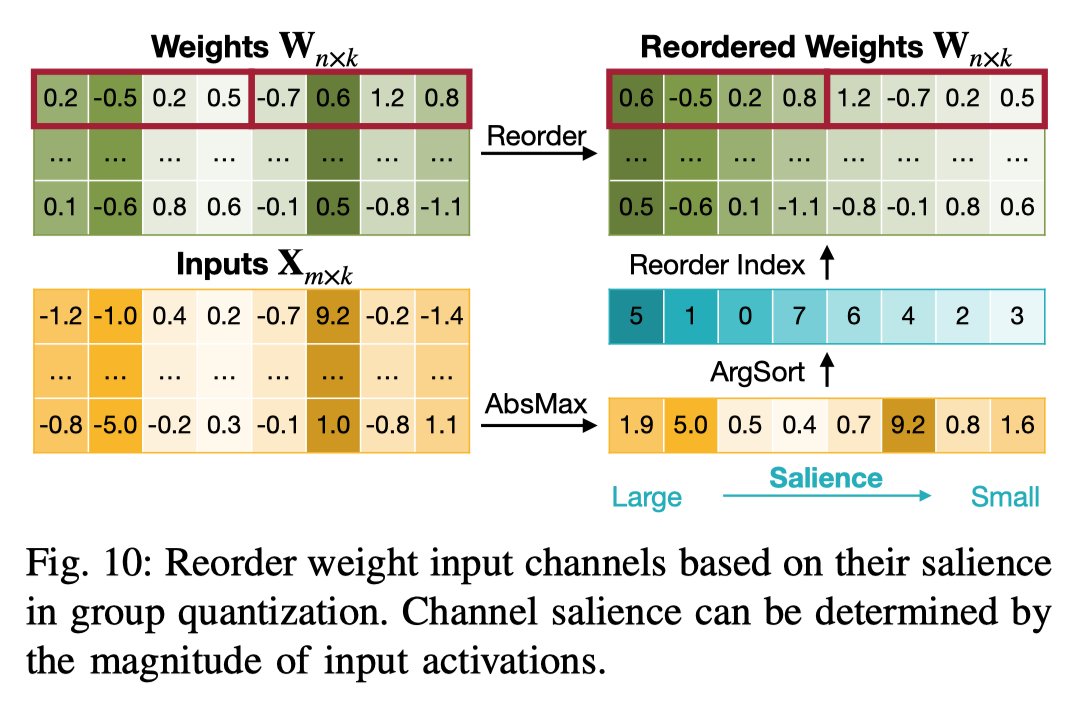
3) Activation-Aware Channel Reordering:这里受到了 AWQ 的启发,将 activation absmax 作为衡量 salience 的指标,然后对 weight 按照 salience 进行排序,最终的效果就是可以让相似 salience 的权重放在一个 group 中做量化,可以参考下面的示意图。
4) Weight Clipping:这个同样是采用了 AWQ 里面的方法,对 weight 进行 clip,通过 grid search 找到最优的 \(\alpha\) 对 weight 的值进行裁剪。
\[\arg\min_{\alpha} \| \operatorname{Block}(\mathbf{X}; \mathbf{W}) - \operatorname{Block}(\mathbf{X}, \mathbf{Q}(\mathbf{W}; \alpha)) \|\]
文章的下一部分主要讲了 QServe System 是如何高效的实现量化的 kernel,这个不是本次要讨论的重点,就不再赘述,感兴趣可以直接去看原始论文,这个部分的篇幅也不少。
Results
实验结果中大部分在分析性能指标,精度指标主要通过 wiki 上的 ppl 和 common-sense task 来度量,不过绝对的数值指标并不是我们关心的重点,我们更关注 ablation 的结果,这样可以发现哪些方法对精度的影响更本质。
文章中对于 ablation 只放了下面这一个实验结果。
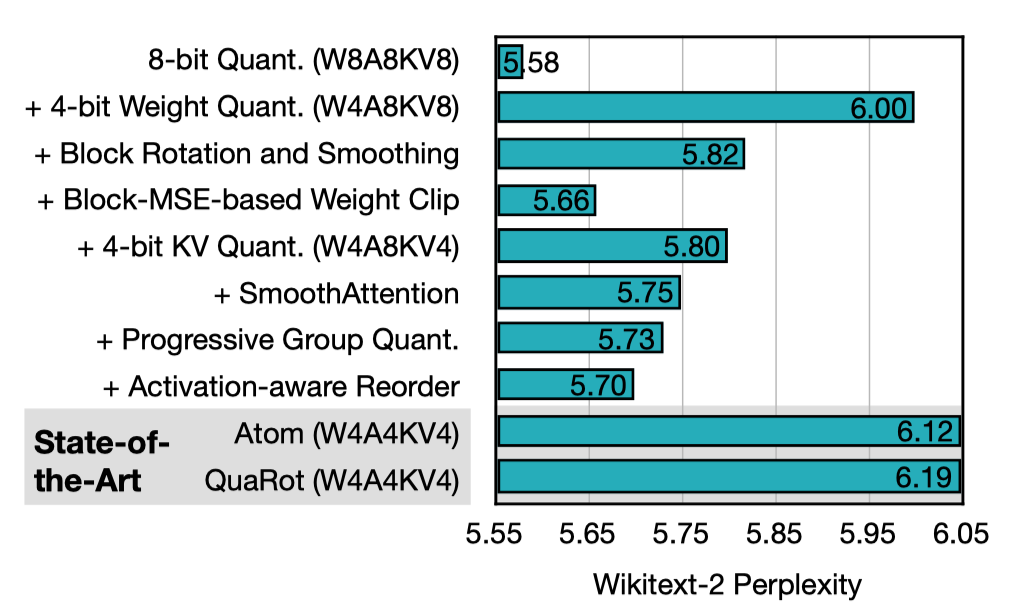
分析上面的结果,将 W8A8KV8 作为 baseline,直接做 W4 的量化就引入了很大的误差,后续的 block-rotate + block-smooth + block-clip 对精度保持起到了比较明显的作用,这就是上面通用优化提到的方法。
后续引入 KV4 又再次增加了精度误差,后续采用的方案,SmoothAttention,Progressive Group Quant 以及 Activation-aware Reorder 剔骨就比较有限了。
方案总结和讨论
上面的文章主要都是在针对低 bit 量化做的探索工作,主要分为 W4 和 KV4 的优化,A4 目前来看精度损失过大,且速度上收益也没有,没有优化的价值。
KV4
对于 KV4 来说,总结之前提到的上面提到的方法如下,排序综合考虑效果和实现难度:
- Per-Channel Key 量化,这个简单高效,而且能有效解决 key 上 outlier 的问题;
- Pre-RoPE Key 量化,这个原理简单,不过对于量化流程,需要修改 transformers forward 代码获得 Pre-RoPE Key,同时需要将 RoPE 放到 attention kernel 里面实现;
- Block Input Module Rotate:通过引入旋转矩阵减弱 outlier 的影响,可以将旋转矩阵 fuse 到上一层的 weight 里面,只需要在量化过程中完成,推理没有额外的工作;
- Dynamic Per-Token Value Quant:因为 attn 里面最终是对 value 的加权求和,采用 per-token 量化可以有效的将 value 量化的误差孤立在每个 token 以内;
- non-uniform 量化,需要在量化过程中引入 k-means 实现非均匀的量化,最终存储的是聚类中心值以及 activation 中每个值对应的 indices,在推理过程中通过 indices select 实现反量化;
- SmoothAttention 将 Key outlier 转移到 Query 上,通过 fuse 到权重上减少 kernel 调用的开销,不过提升比较有限。因为我们已经可以对 key 做 per-channel 量化来消除结构化 outlier 的影响,而相比之下 SmoothQuant 有效的原因是因为要跑 int8 GEMM,所以不能在 X 的
C_in上做 per-channel 量化,只能做 per-token 量化,所以没办法解决 outlier 的问题; - Dense-and-Sparse 过滤出 outliers 单独计算,精度收益很小,实现也比较麻烦,需要分别对 dense 和 sparse 存两个 cache;
- Q-Norm 这个方案就不说了,基于 non-uniform 的聚类中心做小的改动,感觉没什么用;
所以综上所述,值得尝试的是前 5 个加粗的方案,优先级从高到低。
W4A8
对于 W4A8 来说,总结上面提到的方法如下,排序综合考虑效果和实现难度:
- Block Output Module Smoothing:这个类似 SmoothQuant,主要是为了减弱 A8 上 outlier 对精度的影响;
- Weight Clipping:只需要在量化过程中通过 grid search 找到最优的 clip factor 对 weight 数值进行 clip,不会影响推理时的 quant kernel,实现也比较简单,看实验结果在精度上也有一定的提升;
- Progressive Group Quantization:这个就是两步量化的方案,避免直接从 16bit 量化到 4bit,而是先量化到 8bit,再量化到 4bit,计算的时候从 4bit 反量化回 8bit,对于精度没什么帮助,不过计算效率会更好;
- Sensitivity-based Non-Uniform:这个方法在看到的时候非常 impressive,从精度结果上看,提升非常巨大,而且有完整的理论支撑。实际上 fp8 量化也可以看成是一种特殊的 non-uniform 方案,因为 fp8 表示的数值并不是均匀分布的。non-uniform 还有一个好处就是可以支持任意混合 bit 位量化,因为量化之后每个元素实际上存储的并不是实际的数值了,而是聚类中心的下标,看上去这个方案更加通用,因为 uniform 量化只是他的一种特例。不过让我比较疑惑的时候目前社区对这个方法用得非常少,虽然 vLLM 里面支持这个方案,但是基本没看到有人在使用,也许这个方法有一些缺陷,不过目前通过看 paper 还没发现有什么问题。
- Activation-Aware Channel Reordering:reorder 从精度上看提升很小,也没明白为什么将相似 salience 的 weight 放在一个 group 里面就能提升精度,同时对于 quant kernel 有需要一些改动,感觉没必要尝试;
- Dense-and-Sparse Quantization:这个和上面 kv cache 一样,提升很小,又比较复杂,不用尝试了;
所以综上所述,值得尝试的是前 4 个加粗的方案,优先级从高到低。