SmoothQuant 原理 Recap
可以用下面这张图简要描述 SQ 的工作原理,由于 LLM 中间的 activation 在某些维度存在 outlier,可以通过对 activation 做 scaling down 来将 outlier 值变小,但是为了保证输出不变,对 weight 做反向的 scaling up。
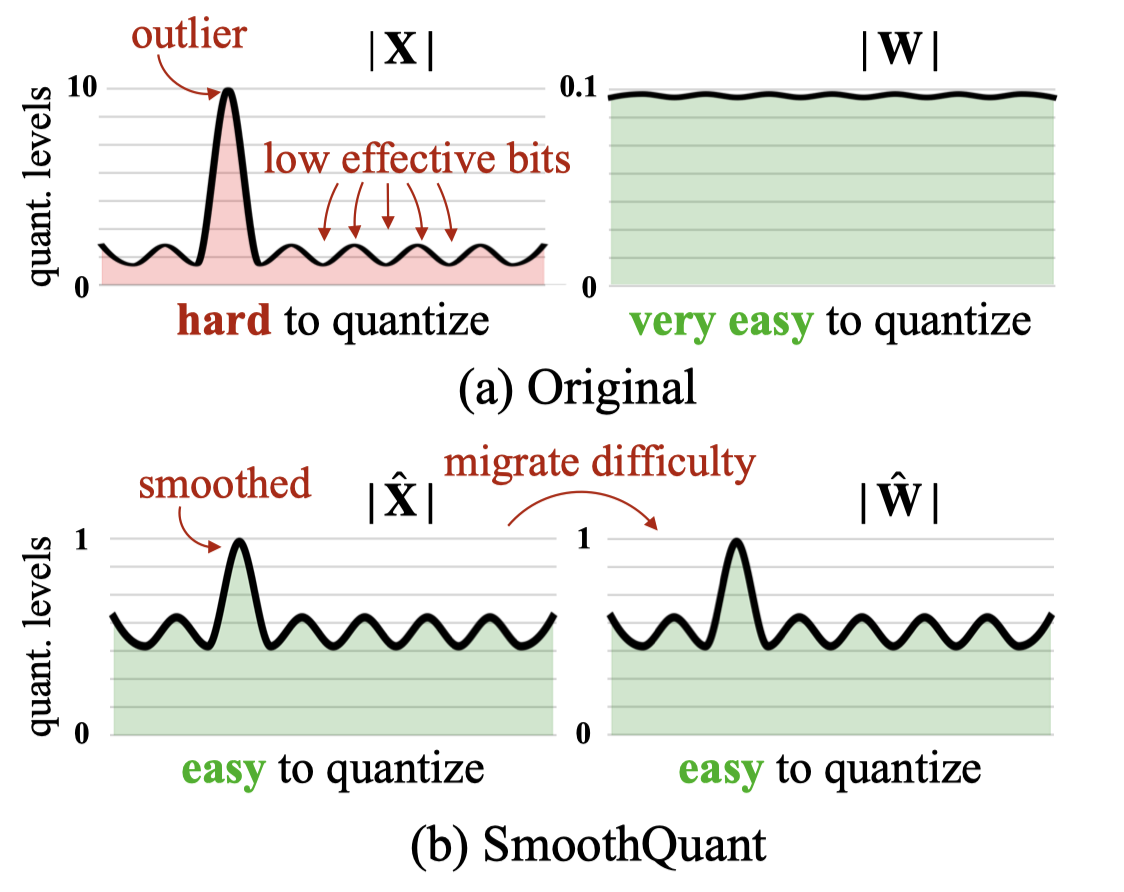
具体来说,对于输入 X: [token, C_in],linear weight W: [C_in, C_out],scaling vector S: [C_in],smooth 的流程即将 X scaling down 为X_1 = X / S.view(1, -1),同时将 W scaling up 为 W_1 = X * S.view(-1, 1)。这里要特别注意 scaling 是作用在 C_in 维度上,因为 outlier 出现的规律是在同一层的特定维度,和常规量化处理 scales 的维度不一样(比如 X 是在 token 维度,weight 是在 C_out 维度)。
而对 activation 做 scaling down 又可以等价于对输出该 activation 对应层的 weight 作用,这样就不需要在模型中插入额外的 scaling 操作,只需要处理相邻两层的 weight 即可。
在获得了更好量化的 activation 之后,采用 int8 对称量化的方式,分别对 activation 和 weight 进行量化,然后使用 int8 gemm 进行计算,最后再将结果反量化。
当前的问题
之前对 SQ 进行了简单的支持,完成了上述 smooth activation 的流程,不过存在下面的一些问题:
在当前 crossing 中,W8A8 只实现了 per-tensor static 推理;
当时只在 llama-7b-chat 上进行了简单的生成测试,观察到生成的 text 是正常的,并没有进一步做 benchmark evaluation。https://github.com/siliconflow/crossingbits/pull/21
smooth 过程只针对了 layernorm-fc 的 pattern,比如 attention 中 attn_layernorm -> QKV_proj。但是除了这种 pattern,还存在 fc-fc 的 pattern,比如 attention 中的 V_proj -> O_proj,如果不处理这种 pattern,fc 中间的 activation 也会出现 outlier。
对于 scale 的计算,采用了固定的
alpha=0.5,但是同一个模型的不同层,以及不同模型对 alpha 的倾向性都不同。scale = ( (act_scale.pow(alpha) / weight_scale.pow(1 - alpha)) .clamp(min=1e-5) )目前
int8_gemmkernel 的返回类型是 fp16,会出现精度问题,需要采用 fp32.
一些 Fixup
首先扩展了量化的类型,增加了 per-token 和 per-tensor 的动态量化,同时将 output dtype 修改为采用 fp32,先采用 torch op 去验证量化流程的正确性。
然后增加了 fc-fc pattern,这个对应 attention 里面的 V_proj -> O_proj,以及 MLP 里面的 gate_proj -> down_proj。
Greedy Search
针对 alpha 进行 layer-wise greedy search,具体来说就是从 0 到 1,以 0.5 为 step 进行遍历计算对应的 scale,然后对 input 和 weight 分别进行 scaling down 和 scaling up 之后,对他们进行量化,然后对量化之后的推理结果和 fp16 推理结果进行比较,选择误差最小的 alpha。
这里遇到的一个问题就是怎么方便的去跑量化模型的结果,不能直接把 linear 替换成 w8a8linear 去跑,因为在 greedy search 的过程中,每次都要恢复 module 的 state_dict,如果做了 linear 的替换,修改回原始的状态会非常不方便,所以最好是只修改 module 里面的 weight,不要进行 linear 的替换。
一个比较方便的解决方法就是采用 hook 机制,首先对 weight 进行 int8 对称量化,然后对于所有需要模拟量化的 linear,通过 register_forward_pre_hook 对输入进行量化,最后通过 register_forward_hook 对结果进行反量化。通过这个方式可以每次 inplace 修改 weight,在每次 search 结束之后,将 state_dict 还原。
def int8_quantize(m, inp):
return (
torch.round(inp[0] / (scales_view * input_scale)).clamp(-128, 127).float()
)
def int8_dequantize(m, inp, out):
return (out * output_scale).to(torch.float16)
quant_hooks.append(fc.register_forward_pre_hook(int8_quantize))
quant_hooks.append(fc.register_forward_hook(int8_dequantize))
FC-FC Smooth
除了 layernorm-fc smooth 流程之外,增加 fc-fc smooth 的支持。这个过程的实现并不复杂,但是结合 greed search 会引入一个新的问题,下面以 attention 举例。
首先进行 layernorm -> QKV_proj 的 smooth 流程,这个过程会修改 layernorm 的 weight 以及 QKV_proj 的 weight,在这一组 search 结束之后会获得一个 error 最小的 alpha 叫做 \(\alpha_1\)。然后开始下一组搜索,V_proj -> O_proj 的 smooth 流程,然后相应修改 V_proj 和 O_proj 的 weight,在搜索结束之后会获得最小 error 的 alpha 叫做 \(\alpha_2\)。
通过上面的流程,就完成了整个 attention 的搜索流程,看上去似乎也没什么问题。但是在 V_proj -> O_proj smooth 过程完成之后,会修改 V_proj 的 weight,假如从 W1 修改为 W2,这就导致 layernorm -> QKV_proj smooth 过程中搜索的 \(\alpha_1\) 可能不是最优的,因为 \(\alpha_1\) 的搜索结果是建立在 V_proj weight 是 W1 的基础上。
那么为什么先做 layernorm -> QKV_proj 的 smooth 不会影响 V_proj -> O_proj 的结果呢?因为 smooth 过程只修改相邻两层的 weight,但是会保证输出的结果不变,即不管如何 smooth,V_proj 输出的结果都是不变的。而 V_proj -> O_proj 的 smooth 过程只依赖 O_proj 的输入,也就是 V_proj 的输出,就不会受影响。
Reverse Greedy Search
如何解决这个问题呢?可以采用 reverse greedy search,即先 search fc-fc smooth,再 search layernorm-fc smooth。
采用这方式,首先找到 V_proj -> O_proj 最优的 \(\alpha_2\),然后相应修改 V_proj 和 O_proj 的 weight,接着再进行 layernorm -> QKV_proj smooth 的搜索,这个时候由于 V_proj 已经从 W1 修改为 W2,那么 \(\alpha_1\) 的搜索就基于 W2,这样就避免了之前基于 W1 搜索到的次优解的问题。
而就像之前写得,不管是否进行 layernorm -> QKV_proj 的 smooth,都不影响 V_proj -> O_proj 的 smooth 过程,所以先做 V_proj -> O_proj 也不会引入其他问题。
实验结果
对于整个 SQ 的流程,除了最终评估模型在测试集上的指标之外,还有一些额外的中间指标可以进行观测,比如搜索出来的 alpha 分布,每一层的量化误差,所有 linear 输入的平均 input scales 大小,都可以一定程度上反应整个优化的效果。
下面所在的实验结果都是基于 code-llama-7b-inst 进行的,指标选择 humaneval-python,量化采用 per-token 动态量化,其中 baseline 是采用 SQ 原始论文的流程,固定 alpha=0.5,只做 layernorm-FC 的 smooth。
| Model | Quant Error | Mean Scale | Pass@1 |
|---|---|---|---|
| FP16 | N/A | N/A | 0.4695 |
| Baseline | 10.569 | 21.701 | 0.445 |
| FC-FC | 12.911 | 2.273 | 0.445 |
| Search from 0-1 | 11.237 | 3.120 | 0.421 |
| Search from 0.5-1 | 5.997 | 2.003 | 0.463 |
| Reverse Search from 0-1 | 5.777 | 2.985 | 0.439 |
| Reverse Search from 0.5-1 | 4.291 | 1.986 | 0.488 |
一些 takeaways:
- 上面并没有 per-tensor static 量化的结果,因为完全没法生成合理的输出。检查了 linear 层的 input 动态计算的 scale 和对应的 PTQ 离线统计出来的 input_scale,发现差别还比较大,应该是 int8 下 input 对 scale 非常敏感,per-tensor 只通过一个标量来表示 scale 太不准了。
- 不同模型对于量化粒度要求不同,比如 llama7b-chat 采用 per-tensor static 也能正常生成 text,但是 codellama-7b-inst 采用 per-tensor static 完全不能吐出来正常的结果。
- 增加了 fc-fc smooth 在 mean scale 上有非常显著的下降,虽然逐层的量化误差增加了一些,但是总的 eval metric 没有什么变化。mean scale 的下降说明 fc-fc smooth 对于整体 input scaling down 还是产生了效果,只是最终对结果影响不大。
- 对 alpha 进行 0 到 1 的 greedy search,各项指标都出现了劣化,分析了其中的问题,发现对于 layernorm -> fc search 的 alpha 都偏小,大概在 0-0.3 的范围内,不符合预期;而 fc -> fc search 出来的 alpha 都在 0.7-1 之间,比较符合预期。对于 fc -> fc search 的过程,我们搜索的指标就是当前 fc 量化前后的推理误差,而对于 layernorm -> fc search 的过程,比如 attn_fc -> qkv_proj,搜索的指标是整个 attention 中 qkv 量化前后的推理误差。通过分析其中的推理误差,发现大部分的误差都比较接近,所以 alpha 的选择容易出现随机性,比如 error 分别是 0.25 和 0.24,由于只是通过离线模拟量化误差,并非 0.24 就更好。
- 限制了 alpha 的范围,从 0 到 1 修改为从 0.5 到 1,因为有一个先验是 input 容易出现 outlier,而 weight 分布是相对正常的。对于 smooth 来说,alpha 越小,越是对 weight 做 scaling down,alpha 越大才是对 input 做 scaling down,所以可以基于这个先验,让 alpha 最小只能是 0.5。通过这个方式,量化误差,scale 以及 eval metric 都变得更好了。
- 增加 reverse 的流程,不管 search range 是
[0, 1]还是[0.5, 1],各项指标都变得更好了,说明方案是有效的。 - 最后的精度比 fp16 还要高,之前在 fp8 的测试也观察到过这个现象,应该还是测试结果存在随机性引起的,可能换一个测试集结论就不一样了,所以应该并不是说量化提升了模型的精度。